汇集公众科学智慧 交流科学思想见解点燃科学智慧火花 构建互动交流平台
汇集公众科学智慧 交流科学思想见解点燃科学智慧火花 构建互动交流平台
机器学习中经常采用的数据预处理有:
(1)min-max标准化(min-max scaling)
对于原始数据x,通过其最小值和最大值,映射成为区间[0,1]中的值:
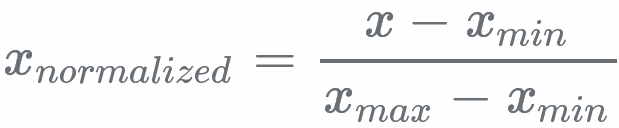 。
。
(2)z-score标准化(z-score standardizd)
采用原始数据x的均值(mean,μ)和标准差(standard deviation,σ)进行数据的标准化:
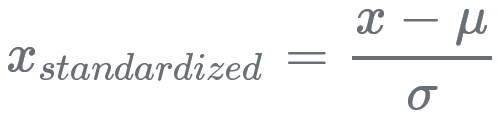 。
。
从数学角度看,经过“减法”、“除法”之后性质仍然不变的系统,一般为“线性系统linear system”,即同时满足
①“叠加性additivity or superposition principle”
f(x+y) = f(x) + f(y),
和
②“齐次性homogeneity”
f(kx) = kf(x),k≠0是一个实数。
的系统f(·)。
对于非线性系统(nonlinear system),由于不同时满足叠加性和齐次性,而min-max标准化、z-score标准化中的减法(“x - xmin”、“x -μ”)、除法分别要求叠加性和齐次性,所以会产生一定的误差。
简言之,min-max标准化、z-score标准化:
(1)对线性系统完全适用;
(2)非线性系统的局部线性化,很好地适用;
(3)非线性系统的全局分析,可能会引起明显的偏差。
所以,要慎用“机器学习中的数据预处理:缩放和中心化”。
例如,在风速的空间相关性预测里,采用Pearson相关系数(Pearson product-moment correlation coefficient)找到的有风速时间序列的参考矢量(红色)的“相似矢量(黑色粗线)”,相当地不合适。请看下图:
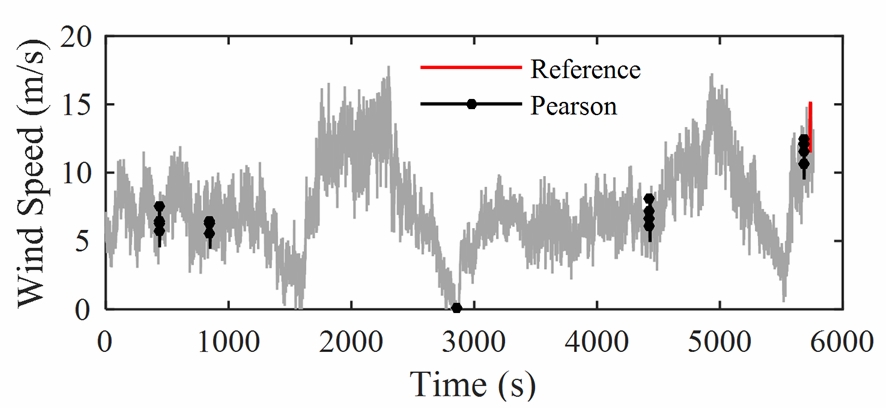
因为Pearson相关系数r采用了减法、除法,
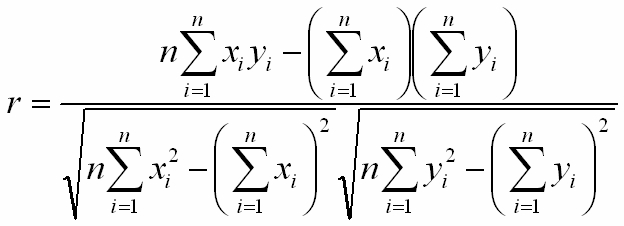
一般只保证对线性系统是完美的。
参考资料:
[1] Hugo Bowne-Anderson,2016-04-27,Preprocessing in Data Science (Part 1): Centering, Scaling, and KNN
https://www.datacamp.com/community/tutorials/preprocessing-in-data-science-part-1-centering-scaling-and-knn
[2] 刘翔宇(翻译),数据科学与机器学习管道中预处理的重要性(一):中心化、缩放和K近邻
https://blog.csdn.net/starzhou/article/details/51473696
[3] Zheng-Ling Yang, Reng-Xiang Liu, Zhen-Zhen Li, et al. An explicit analytical estimation of the validity of the Tanimoto similarity by confidence intervals in mathematical statistics[C]. WCICA 2018,录用。