
汇集公众科学智慧 交流科学思想见解点燃科学智慧火花 构建互动交流平台
汇集公众科学智慧 交流科学思想见解点燃科学智慧火花 构建互动交流平台
一、深度学习的定义
近年来,人们在越来越多的领域遇到“深度学习”,“机器学习”,“人工智能”等术语,但是,它们究竟是什么意思?具体可以应用在哪里呢?“深度”究竟指得是什么?在百度百科上,“深度学习”被定义为——深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。看起来似乎依旧让人一头雾水。。。
“深度学习”是机器学习的子领域,而机器学习又被视为人工智能的子领域(如图1),所以,想要了解深度学习,就必须对机器学习和人工智能有一定了解。
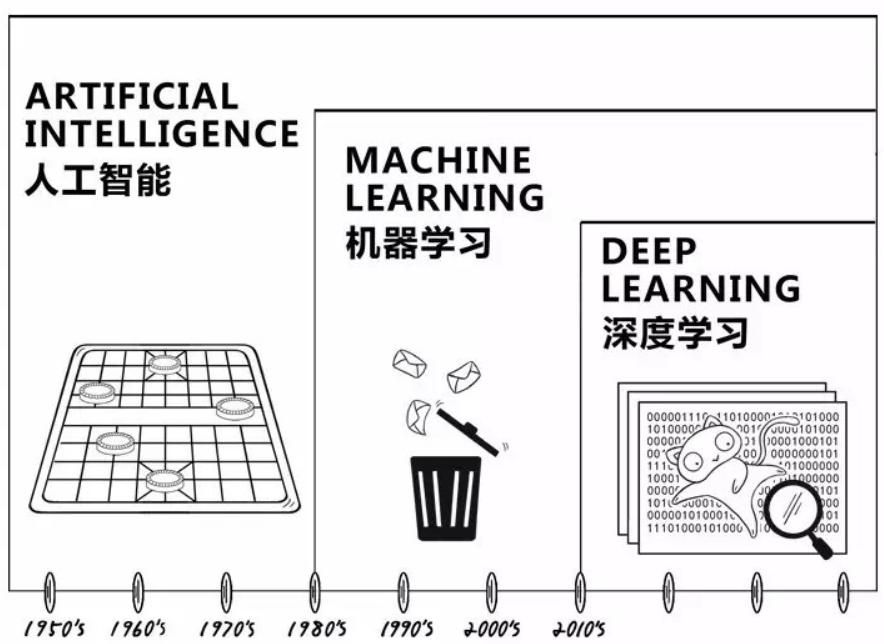
图1:人工智能、机器学习、深度学习的关系
1.人工智能(AI)
人工智能(Artificial Intelligence, AI)是机器,特别是计算机系统对人类智能过程的模拟。人工智能是一个愿景,目标就是让机器像我们人类一样思考与行动,能够代替我们人类去做各种各样的工作。
人工智能研究的范围非常广,包括演绎、推理和解决问题、知识表示、学习、运动和控制、数据挖掘等众多领域。其中,知识表示是人工智能领域的核心研究问题之一,它的目标是让机器存储相应的知识,并且能够按照某种规则推理演绎得到新的知识。许多问题的解决都需要先验知识。
举个例子,当我们说“林黛玉”,我们会联想到“弱不禁风”“楚楚可怜”的形象,与此同时,我们还会联想到林黛玉的扮演者“陈晓旭”。如果没有先验的知识,我们无法将“林黛玉”和“陈晓旭”关联起来。在这里,“林黛玉”“陈晓旭”都是实体(也称为本体),实体与实体之间通过某种关系连接起来,实体、实体间的关系该如何存储、如何表示、如何方便地应用到生产和生活中,这些都是知识表示要研究的课题。
人工智能利用不同的方法对人类行为和决策结构进行模仿,有关方法包括统计算法、启发式程序,按照是增强我们脑力还是增强我们体力、是取代人的工作还是辅助人,可以根据应用场景划分成如图2的4个大的类别。
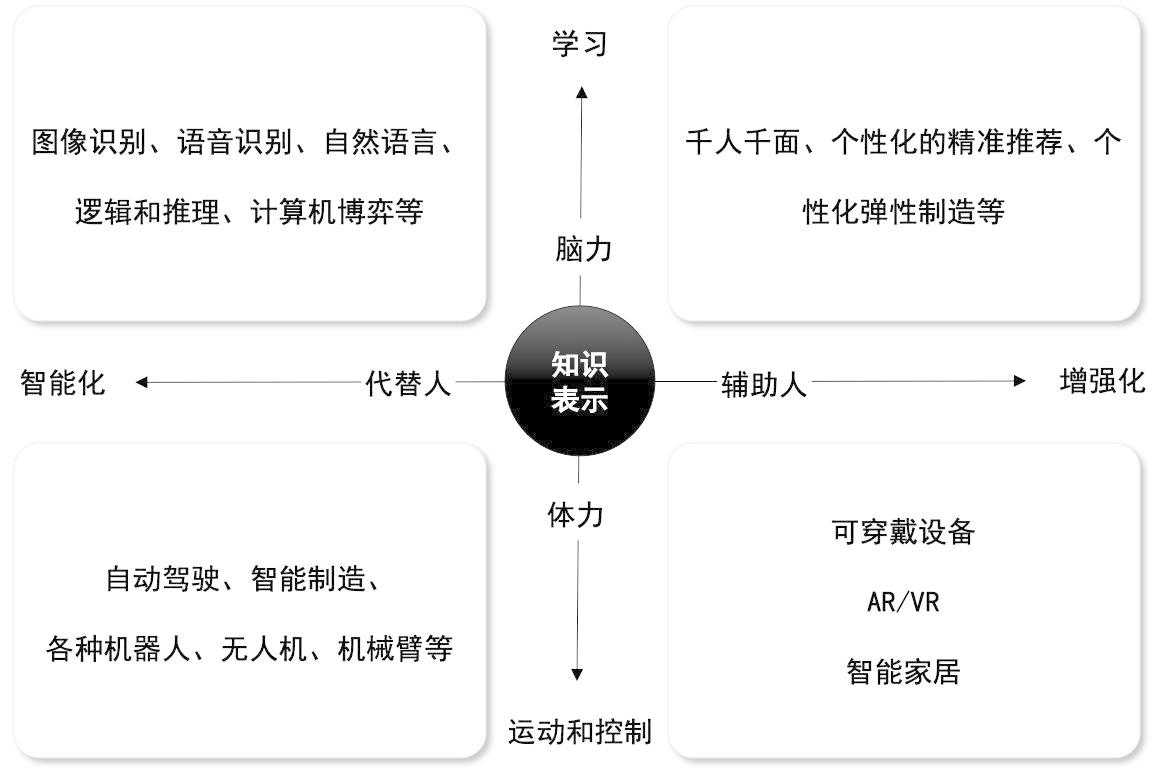
图2:人工智能的4大应用场景
2. 机器学习(ML)
机器学习是AI的子领域,是机器从经验中自动学习和改进的过程,不需要人工编写程序指定规则和逻辑。它由一系列自动程序组成,可以从一组示例数据推演出基本规则,即通过示例数据来“习得”规则(如图3)。
“学习”的目的是获得知识。机器学习的目的是让机器从用户和输入数据处获得知识,以便在生产、生活的实际环境中,能够自动作出判断和响应,从而帮助我们解决更多问题、减少错误、提高效率。
一般来说,机器学习中的预处理、特征提取、特征选择概括起来叫做特征表达,特征表达对算法的准确率起到决定性作用,这一部分靠人工提取特征的方法有很多,但是操作起来复杂且繁琐。
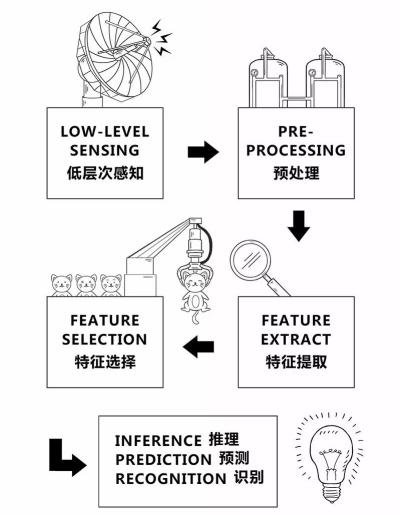
图3:机器学习的处理流程
3.深度学习
深度学习是一种机器学习方法(Deep Learning)用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。最显著的应用是计算机视觉和自然语言处理(NLP)领域。
它作为人工神经网络可以根据学习过程中的示例数据来独立地构建(训练)出基本规则(图4),其将特征提取和分类结合到一个框架中,用数据学习特征,是一种可以自动学习特征的方法,如图5所示,深度学习会自动学习特征,然后通过一系列原理,将未知数据识别出来,那深度学习的工作原理是什么呢?
图4:深度学习的独立学习能力
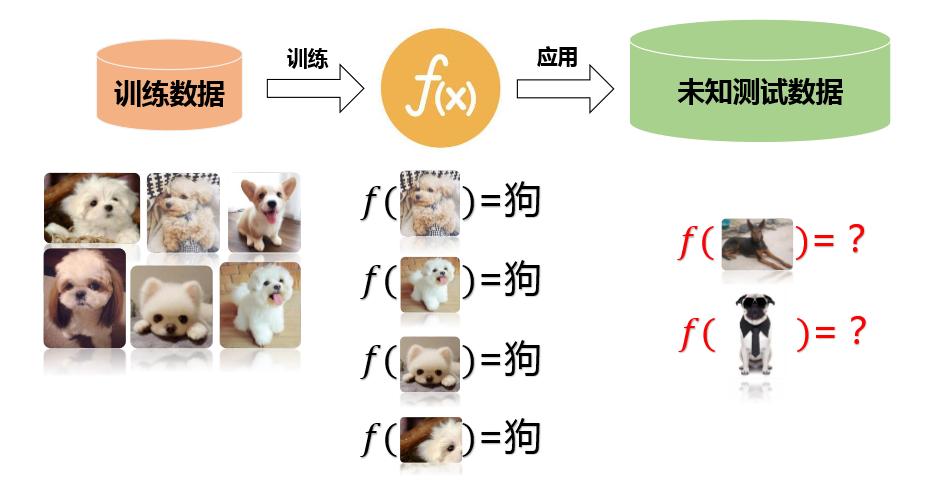
图5:深度学习识别未知数据流程
一、深度学习的工作原理与工作流程
1. “深度”如何理解?
“深度”指的并不是利用深度学习这种方法能够获取更加深层次的理解,而是指一系列连续的层。数据模型中包含多少层,被称为模型的深度。机器学习往往仅学习一两层数据表示,但是深度学习一般是多层网络。下图展示的是多层网络如何对数字图像进行变换,以便识别图像中所包含的数字(图6)。
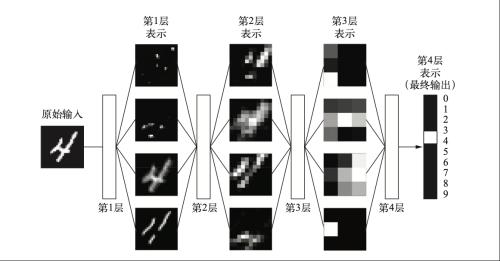
图6:深度学习识别图像数字流程
2. 神经网络如何对数据进行处理操作?
神经网络对输入数据的具体操作保存在该层的 “权重”中,每层实现的变换由其权重来参数化。“学习”就是为神经网络的所有层找到一组权重值,使得该网络能够将输入与我们的目标输出一一对应(图7)。
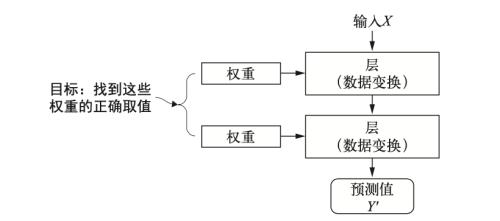
图7:神经网络层权重赋值
3. 如何让确定输出值与预期值的关系?
要让神经网络知道它的输出是否为人们所期待的,我们就需要一个衡量标准来衡量该输出与预期值之间的距离,我们也叫这个距离为损失。损失需要靠神经网络中损失函数(loss function)来丈量,损失函数也叫目标函数(图8)。
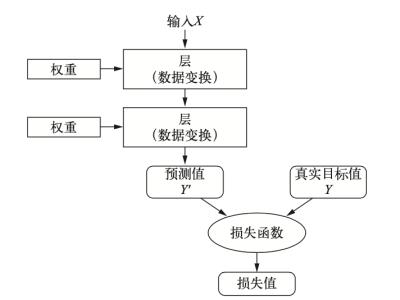
图8:损失函数
4.如何进行“学习”?
利用我们得到的距离值(损失)作为反馈信号来进行参数微调,以降低当前的损失值。这个调节由优化器(optimizer)来完成,它实现了所谓的反向传播(backpropagation)算法,这也是深度学习的核心算法。
一开始对神经网络的权重是随机赋值的,然后经过不断的训练循环(training loop),不断微调权重,使得损失值越来越小,我们的精度也越来越高。这就逐步得到人们想要的深度学习模型(图9)。
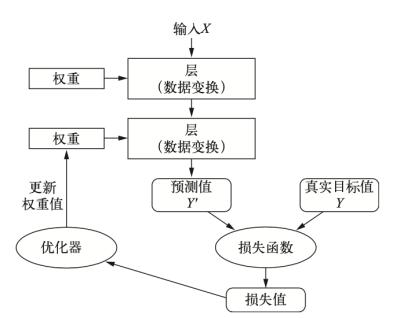
图9:深度学习流程
三、“深度学习”的欠拟合与过拟合
随着计算机性能的稳定提升及大数据的不断发展,算法、数据、机器性能不断提高,而深度学习在数据和层数足够多时,优势越发明显,如图10所示。
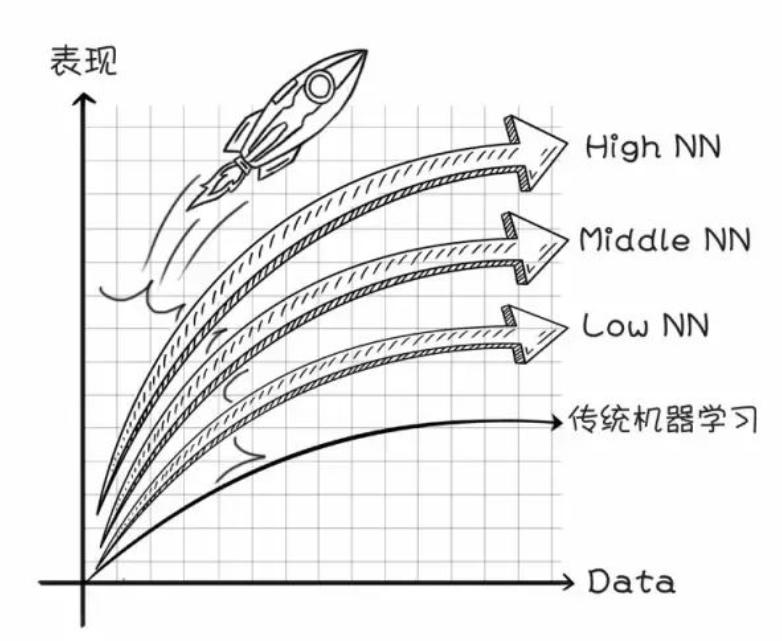
图10:深度学习的优势
虽然大数据无处不在,但是可用来进行深度学习的可用数据却是有限的,通常情况下,人们将获得的数据分为两个部分,一个部分用来训练,一个部分用来测试,称为训练集和测试集。
如果一个深度学习的模型在训练时表现很差,测试也很差,像一个“学渣”,则把该模型称为“欠拟合”(图11)。
如果一个模型在训练时表现优异,测试时却很差,就像死记硬背型学渣,过分执着于偏难怪题(噪声),不懂预测、灵活性差,则把该模型称之为“过拟合”(图12)。

四、深度学习的应用
1.计算机视觉
(1)目标检测
目标检测(Object Detection)是当前计算机视觉和机器学习领域的研究热点之一,核心任务是筛选出给定图像中所有感兴趣的目标,确定其位置和大小。其中难点便是遮挡,光照,姿态等造成的像素级误差,这是目标检测所要挑战和避免的问题。现如今深度学习中一般通过搭建DNN提取目标特征,利用ROI映射和IoU确定阈值以及区域建议网络RPN统一坐标回归损失和二分类损失来联合训练(图13)。

图13:目标检测流程
(2)语义分割
语义分割(Semantic Segmentation)旨在将图像中的物体作为可解释的语义类别,该类别将是DNN学习的特征聚类得到。和目标检测一样,在深度学习中需要IoU作为评价指标评估设计的语义分割网络。值得注意的是,语义类别对应于不同的颜色,生成的结果需要和原始的标注图像相比较,较为一致才能算是一个可分辨不同语义信息的网络(图14)。
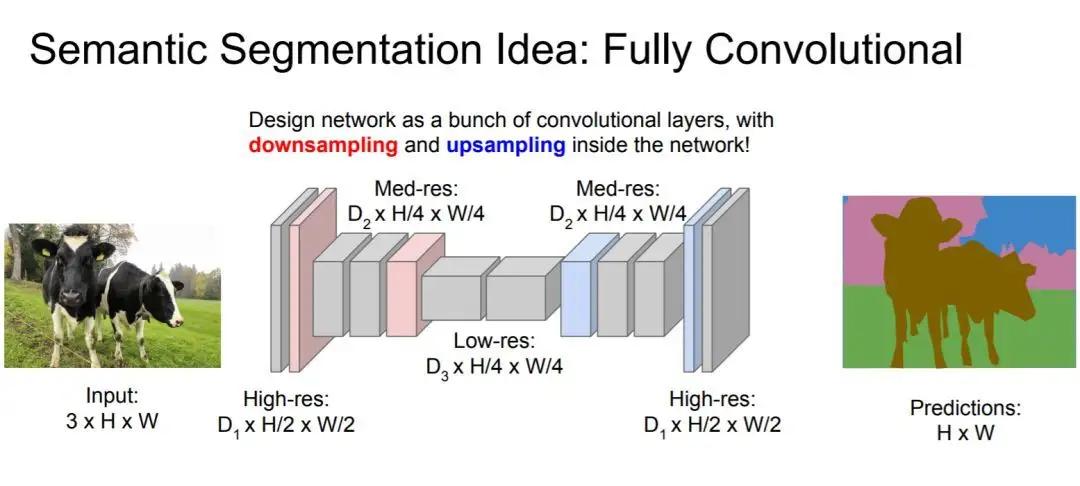
图14:语义分割流程
(3)超分辨率重建
超分辨率重建(Super Resolution Construction)的主要任务是通过软件和硬件的方法,从观测到的低分辨率图像重建出高分辨率图像,这样的技术在医疗影像和视频编码通信中十分重要。该领域一般分为单图像超分和视频超分,一般在视频序列中通过该技术解决丢帧,帧图像模糊等问题,而在单图像在中主要为了提升细节和质感。在深度学习中一般采用残差形式网络学习双二次或双三次下采样带来的精度损失,以提升大图细节;对于视频超分一般采用光流或者运动补偿来解决帧图像的重建任务。
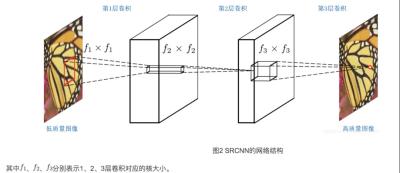
图15:超分辨率重建流程
(4)行人重识别
行人重识别(Person Re-identification)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。其广泛被认为是一个图像检索的子问题。核心任务是给定一个监控行人图像,检索跨设备下的该行人图像。现如今一般人脸识别和该技术进行联合,用于在人脸识别的辅助以及人脸识别失效(人脸模糊,人脸被遮挡)时发挥作用。在深度学习中一般通过全局和局部特征提取和以及度量学习对多组行人图片进行分类和身份查询(图16)。
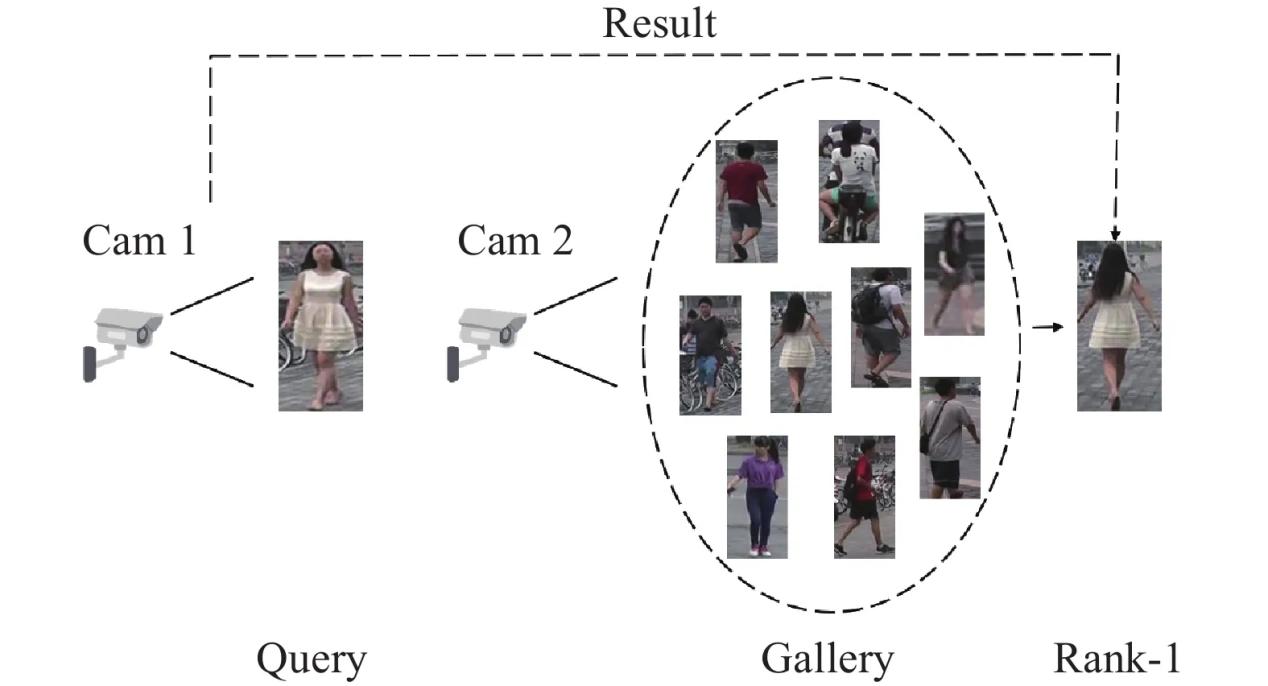
图16:行人重识别流程
2.语音识别
语音识别(Speech Recognization)是一门交叉学科,近十几年进步显著。除了需要数字信号处理,模式识别,概率论等理论知识,深度学习的发展也使其有了很大幅度的效果提升。深度学习中将声音转化为比特的目的类似于在计算机视觉中处理图像数据一样,转换为特征向量,与图像处理不太一样的是需要对波(声音的形式)进行采样,采样的方式,采样点的个数和坐标也是关键信息,然后对这些数字信息进行处理输入到网络中进行训练,得到一个可以进行语音识别的模型。语音识别的难点有很多,例如克服发音音节相似度高进行精准识别,实时语音转写等,这就需要很多不同人样本的声音作为数据集来让深度网络具有更强的泛化性,以及需要设计的网络本身的复杂程度是否得当等条件(图17)。
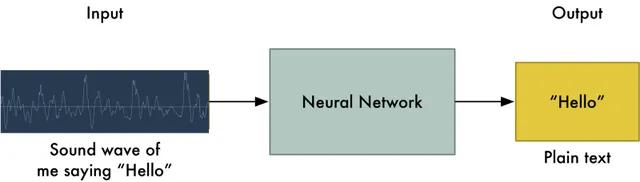
图17:语音识别流程
3.自然语言处理
自然语言处理(NLP)是计算机科学和人工智能领域的方向之一,研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。深度学习由于其非线性的复杂结构,将低维稠密且连续的向量表示为不同粒度的语言单元,例如词、短语、句子和文章,让计算机可以理解通过网络模型参与编织的语言,进而使得人类和计算机进行沟通。此外深度学习领域中研究人员使用循环、卷积、递归等神经网络模型对不同的语言单元向量进行组合,获得更大语言单元的表示。不同的向量空间拥有的组合越复杂,计算机越是能处理更加难以理解的语义信息。将人类的文本作为输入,本身就具有挑战性,因此得到的自然语言计算机如何处理就更难上加难,而这也是NLP不断探索的领域。通过深度学习,人们已经在AI领域向前迈出一大步,相信人与机器沟通中“信、达、雅”这三个方面终将实现。
五、深度学习相关框架
武侠小说里面我们经常可以看到剑法高超的侠客手持长剑,而他们手中的“剑”名称不一,用法也不同,但却能凭此一较高下。深度学习也是一样,需要这样的“剑”来展现剑招和较量,而这些“剑”就是深度学习框架,没有这些框架,我们就不能实现深度学习任务。下面对一些框架进行简单介绍。
1.Caffe
全称是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,核心语言是C++并支持命令行、Python和MATLAB接口,然而比较困难的是搭建环境和代码编写,由于Visual Studio版本更迭以及一些相关必备运行库的编译过程复杂问题,使得使用Caffe的研究人员相较于之前大幅度减少,而且如果希望模型可以在GPU训练,还需要自己实现基于C++和CUDA语言的层,这对于编程难度很大,更加对入门人员不友好。
2.TensorFlow
一经推出就大获成功的框架,采用静态计算图机制,编程接口支持C++,Java,Go,R和Python,同时也集成了Keras框架的核心内容。此外,TensorFlow由于使用C++ Eigen库,其便可在ARM架构上编译和模型训练,因此可以在各种云服务器和移动设备上进行模型训练,而华为云的多模态开发套件HiLens Kit已经利用TensorFlow这一特点具备了开发框架的搭载,外部接口的管理和算子库封装等功能,可一键部署和一键卸载。可以说TensorFlow使得AI技术在企业中得到了快速发展和广泛关注,也使得越来越多的人使用深度学习进行工作。然而,其缺点也很让人苦恼,一是环境搭建,二是复杂设计,让研究人员针对不断改变的接口有心无力,bug频出。然而,如果具有一个良好的开发平台,就可以解决这些显而易见的问题。例如,全面升级的华为云ModelArts 2.0一站式AI开发与管理平台,通过全流程的自动化升级已有的AI开发模式,让模型训练、模型管理、数据准备、模型推理全链条产生质的飞越。华为云ModelArts 2.0,一方面可以显著提升专业AI开发者的效率,让数据科学家、算法工程师们聚焦基础核心的算法研究与创新,释放他们的无限潜能。另一方面,也可以大幅降低初学者的门槛,让更多的AI爱好者可以快速掌握AI技能,为更多行业创造新价值。
3.PyTorch
前身是Torch,底层和Torch框架一样,Python重写之后灵活高效,采用动态计算图机制,相比TensorFlow简洁,面向对象,抽象层次高。对于环境搭建可能是最方便的框架之一,因此现如今基本上很多的论文都是PyTorch实现,代码和教程也非常多,对入门人员友好,计算速度快,代码易于阅读。许多企业如今使用PyTorch作为研发框架,不得不说PyTorch真的是一个非常厉害的深度学习工具之一。
4.Keras
类似接口而非框架,容易上手,研究人员可以在TensorFlow中看到Keras的一些实现,很多初始化方法TensorFlow都可以直接使用Keras函数接口直接调用实现。然而缺点就在于封装过重,不够轻盈,许多代码的bug可能无法显而易见。
5.Caffe2
继承了Caffe的优点,速度更快,然而还是编译困难,研究人员少,值得一提的是已经并入了PyTorch,因此我们可以在新版本的PyTorch中体会到它的存在。
6.MXNet
支持语言众多,例如C++,Python,MATLAB,R等,同样可以在集群,移动设备,GPU上部署。MXNet集成了Gluon接口,就如同torchvision之于PyTorch那样,而且支持静态图和动态图。然而由于推广力度不够使其并没有像PyTorch和TensorFlow那样受关注,不过其分布式支持却是非常闪耀的一点。
参考文献:
[1] 基于卷积神经网络的遥感图像目标检测[J].刘祥.微型电脑应用.2021(07)
[2] 基于深度学习的遥感图像目标检测与识别[J].史文旭,鲍佳慧,姚宇.计算机应用.2020(12)
[3] 遥感图像目标检测的数据增广研究[J].张磊,张永生,于英,耿彦龙,王贺.测绘科学技术学报.2019(05)无人机海监测绘技术应用下舰船遥感图像目标检测[J].安洁玉,丁斌芬.舰船科学技术.2019(24)
[4] 基于多尺度特征稠密连接的遥感图像目标检测方法[J.张裕,杨海涛,刘翔宇.中国电子科学研究院学报.2019(05)基于显著性特征和角度信息的遥感图像目标检测[J].袁星星,吴秦.计算机科学.2021(04)
[5] 改进区域建议的遥感图像目标检测方法研究[J].姜德文,和晓军.沈阳理工大学学报.2022(01)
[6] 基于软硬件协同加速框架的遥感图像目标检测[J].谭金林,范文童,刘亚虎,梁志锋,王粱,刘斌,黄斌.计算机与现代化.2022(06)基于深度学习的光学遥感图像目标检测研究进展[J].刘小波,刘鹏,蔡之华,乔禹霖,王凌,汪敏.自动化学报.2021(09)
[7] 多阶段遥感图像目标检测方法研究[J].孟曦婷,计璐艳.计算机与现代化.2020(09)
[8] PCAN—Part-Based Context Attention Network for Thermal Power Plant Detection in Remote Sensing lmagery [J]. Yin Wenxin,Dlao Wenhui./Wang Peijin,Gao Xin,Li Ya,Sun Xian. Remote Sensing . 2021 (7)
[9] Leaming a robust CN-based rotation insensitive model for ship detection in VHR remote sensing images [l ] . Dong,Lin. International Journal of Remote Sensing . 2020 (9)
[10] BMF-CNN: an object detection method based on multi-scale feature fusion in VHR remote sensing images[J . Dong,Lin. Remote Sensing Letters . 2020(3)
[11] AVDNet. A Small-Sized Vehicle Detection Network for Aerial Visual Data [J]. Mandal Murari,Shah Manal,Meena Prashant,DeviSanhita VipparthiSantosh Kumar. IEEE Geoscience and Remote Sensing Letters . 2020(3)
[12] Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SARImagery [J .Peng Chen, Ying Lj,HuiZhou,Bingxin Liu,Peng Liu. Journal of Marine Science and Engineering . 2020(2)
[13] ANew Fiamework for Automatic Airports Extraction from SAR Images Using Muili-Level Dual Attention Mechanism [lJ] . Lifu Chen,Siyu Tan,Zhouhao Pan,Jin Xing,Zhihui Yuan,Xuemin Xing,Peng Zhang. Remote Sensing . 2020(3)
[14] Orientation guided anchoring for geospatal object detection from remote sensing imagery [J] . Yongtao Yu,Haiyan GuanDilong Lj Tiannan Gu,E.Tang,Aixia Li. ISPRS Journal of Photogrammetry and Remote Sensing . 2020(C)
[15] SRUN:Spectral Regularized Unsupevised Networks for Hyperspectral Target Detection[J]. Xie Weiying, Yang Jian,Lei Jie,Li Yunsong,Du Qian,He Gang.IEEE Transactions on Geoscience and Remote Sensing . 2020 (2)
